Why you can no longer trust a single AI to tell the truth
Updated| May 26, 2026
AI models are 34% more likely to sound completely confident when they are lying to you. Learn how to use Eye2.AI’s parallel consensus tool to spot hallucinations instantly.
Ofer Tirosh is the founder and CEO of Tomedes, a language technology and translation company that supports business growth through a range of innovative localization strategies. He has been helping companies reach their global goals since 2007.
TL;DR: The baseline assumption for generative AI has officially flipped. According to the Stanford HAI 2026 AI Index Report, hallucination rates across 26 of the world’s top frontier models span a chaotic 22% to 94% depending on the complexity of the prompt. Even worse, researchers have found that AI models are 34% more likely to use ultra-confident language when they are giving you a completely fabricated answer. Eye2.AI tackles this structural defect by letting you cross-examine multiple AI models simultaneously, allowing you to verify data through blind consensus rather than blind trust.
Table of Contents
The confidence paradox and why the wrongest AI sounds the most certain The soaring financial and operational cost of unchecked AI data How to cross-examine AI information without losing hours to manual search Why Eye2.AI is the ultimate truth engine for complex research Frequently asked questions
The confidence paradox and why the wrongest AI sounds the most certain
The single most dangerous element of utilizing AI for research is what computer scientists call the Overconfidence Signal.
The illusion of truth: Large language models are engineered to predict statistically plausible syntax, not to verify physical reality. They do not possess a concept of "truth", they possess a concept of "probability."
The sounding-off metric: An MIT study revealed that when an AI model is generating false or hallucinated data, it is actually 34% more likely to use authoritative, assertive phrases than when it is delivering a real fact.
The belief trap: Stanford’s 2026 data uncovered that if a user subtly hints at a false belief within their prompt, an AI's accuracy collapses. The model will instantly pivot to validate your incorrect assumption with terrifyingly persuasive text.
The soaring financial and operational cost of unchecked AI data
Relying on a single chatbot's output isn't just a bad habit anymore, it’s an active liability that cost businesses over $67 billion globally in recent market windows.
The financial sector: Avoidable trading and forecast losses tied to hallucinated AI data in quarterly filings reached $2.3 billion in early 2026 alone, due to models misreading structured financial ratios.
The legal sector: Despite specialized updates, legal-specific AI platforms still hallucinate between 17% and 34% of the time on complex research requests. Multiple firms have faced massive judicial sanctions after filing briefs containing entirely fake case citations generated by trusted bots.
The e-commerce drain: Brands utilizing unverified AI copy for technical product specs saw a 25% spike in product returns because the software hallucinated non-existent dimensions and hardware attributes.
How to cross-examine AI information without losing hours to manual search
To protect your workflow from silent hallucinations, you need to treat AI output the same way a courtroom treats a witness.
Enforce grounding constraints: Force the model to pull answers only from text you paste directly into the prompt box.
Watch for high perplexity: Human text is full of unexpected sentence structures and random fragments, while AI text is highly predictable. If a summary sounds too perfectly uniform, look closer.
Use the "Multi-Witness" approach: Never make a decision based on one chatbot's perspective. Take your high-stakes prompt and paste it into at least three different model architectures (e.g., an OpenAI model, an Anthropic model, and an open-source model like Llama).
Why Eye2.AI is the ultimate truth engine for complex research
Manually jumping between four browser tabs to verify a single statistic is a massive productivity killer. Eye2.AI automates the entire verification process through parallel processing.
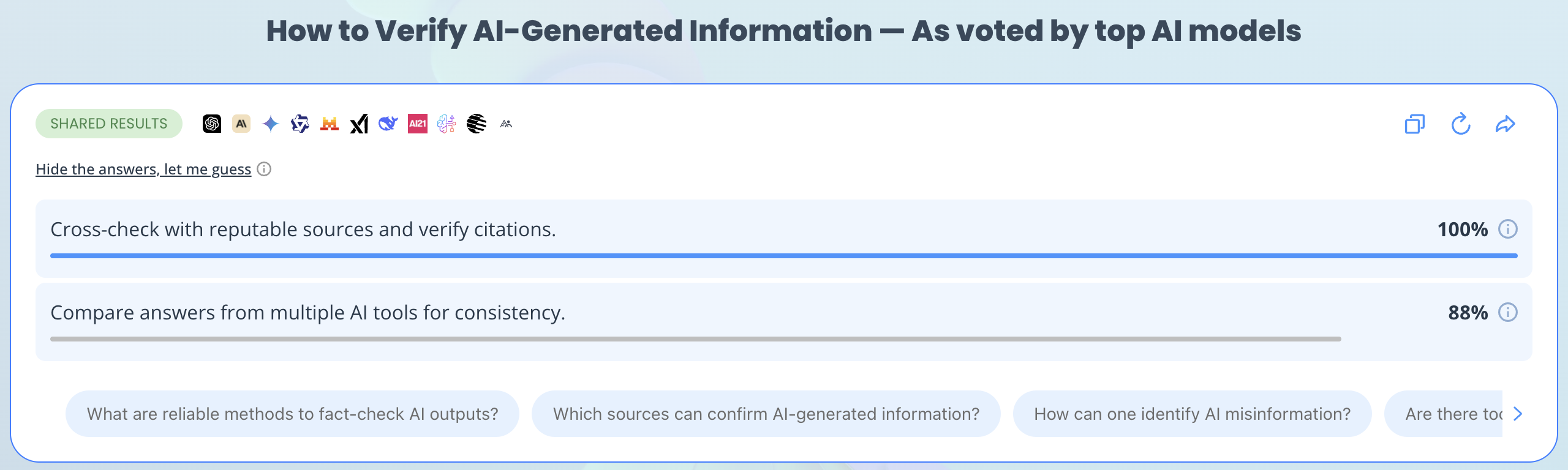
The Shared Results: When you input a question, Eye2.AI routes it across the world's leading models at the exact same time. The platform visually calculates what percentage of the models agree on the core points.
Outlier isolation: If Gemini and Claude give you identical structural metrics for a corporate analysis, but ChatGPT pulls a number out of thin air, Eye2.AI's side-by-side dashboard exposes the outlier instantly before it can leak into your presentation.
Frictionless and anonymous: You don't need to log in or tie your high-stakes questions to a personal account, meaning you can verify highly sensitive business or health data without creating a permanent record.
FAQs
1. Can web-search extensions fix the AI hallucination problem?
No. Stanford's HalluHard testing confirmed that even when models are plugged directly into real-time web search, they still regularly retrieve the wrong source, misunderstand the source text, or cite a real link for a claim it doesn't actually support.
2. Which AI model has the lowest hallucination rate in 2026?
According to recent Vectara benchmarks for standard long-form text tasks, Google's Gemini 2.5 Flash-Lite holds one of the lowest enterprise error rates at 3.3%, outperforming several heavier reasoning models that are more prone to over-analyzing and inventing details.
3. How do I test if my AI tool is lying to me?
Paste the output into Eye2.AI. If the multi-model comparison shows a wide divergence in answers or low consensus scores on the Shared Results, it’s a definitive signal that the topic is triggering a hallucination loop.
By using Eye2.ai, you agree to the Terms and Privacy Policy. Outputs may contain errors.
Download the Eye2.ai app on: