Why you can no longer trust a single AI for high-stakes research
Updated| June 23, 2026
Think your favorite chatbot is giving you accurate research data? These real error rates will shock you. Learn how Eye2.AI exposes model hallucinations instantly.
Ofer Tirosh is the founder and CEO of Tomedes, a language technology and translation company that supports business growth through a range of innovative localization strategies. He has been helping companies reach their global goals since 2007.
TL;DR: The baseline assumption for academic and corporate research has officially flipped. Recent evaluations show that when a single AI model is tasked with parsing dense literature, its hallucination rate can climb up to 24% on complex data extraction—yet it will format those errors with absolute, authoritative confidence. Eye2.AI targets this structural research flaw. By letting you cross-examine 12+ elite AI models simultaneously, it transforms your workflow from blind trust into a rigorous, multi-model verification system.
Table of Contents
The illusion of accuracy in solitary AI research The hidden flaws of relying on standard RAG systems How to build a bulletproof AI research verification framework Why Eye2.AI is the ultimate playground for rapid data validation Frequently asked questions
The illusion of accuracy in solitary AI research
The single most dangerous element of utilizing a single conversational AI for research is what computer scientists call the Overconfidence Signal.
The probability trap: Large language models are engineered to predict statistically plausible syntax, not to verify physical reality. They do not possess a concept of "truth", they possess a concept of "probability."
The authority bias: A model is structurally optimized to sound incredibly confident. When it completely fabricates a citation or a mathematical value within a research brief, it formats that error using the exact same professional, academic tone as its correct answers, making manual spotting nearly impossible.
The confirmation echo: If a user subtly hints at a false hypothesis within their initial research prompt, a single model will routinely pivot to validate your incorrect assumption with terrifyingly persuasive text rather than correcting you.
The hidden flaws of relying on standard RAG systems
Many enterprise teams attempt to solve this accuracy problem by plugging their documents into standard Retrieval-Augmented Generation (RAG) tools, assuming it creates a flawless "closed-circuit" repository.
While grounding models in specific documents reduces baseline hallucinations significantly, standard single-model RAG architectures still suffer from severe blind spots. If a source PDF contains a complex multi-column table or non-linear legal formatting, a single model can easily misinterpret syntax, cross-contaminate disparate variables, or completely omit critical conditional caveats tucked away in the footnotes.
How to build a bulletproof AI research verification framework
To protect your high-stakes corporate or academic findings from silent hallucinations, you need to treat AI output the same way a courtroom treats a witness.
Enforce hard grounding constraints: Explicitly command the model to pull answers only from text you provide, forcing it to state "I don't know" if the fact isn't present.
Isolate semantic outliers: Never make a decision based on one chatbot's perspective. Paste your high-stakes prompt into multiple competing model architectures (e.g., an OpenAI model, an Anthropic model, and an open-source model like Llama).
Cross-examine the reasoning: Look for divergence in how different systems break down a problem step-by-step. If two architectures arrive at different conclusions using the same data, the logic is immediately flagged for human review.
Why Eye2.AI is the ultimate playground for rapid data validation
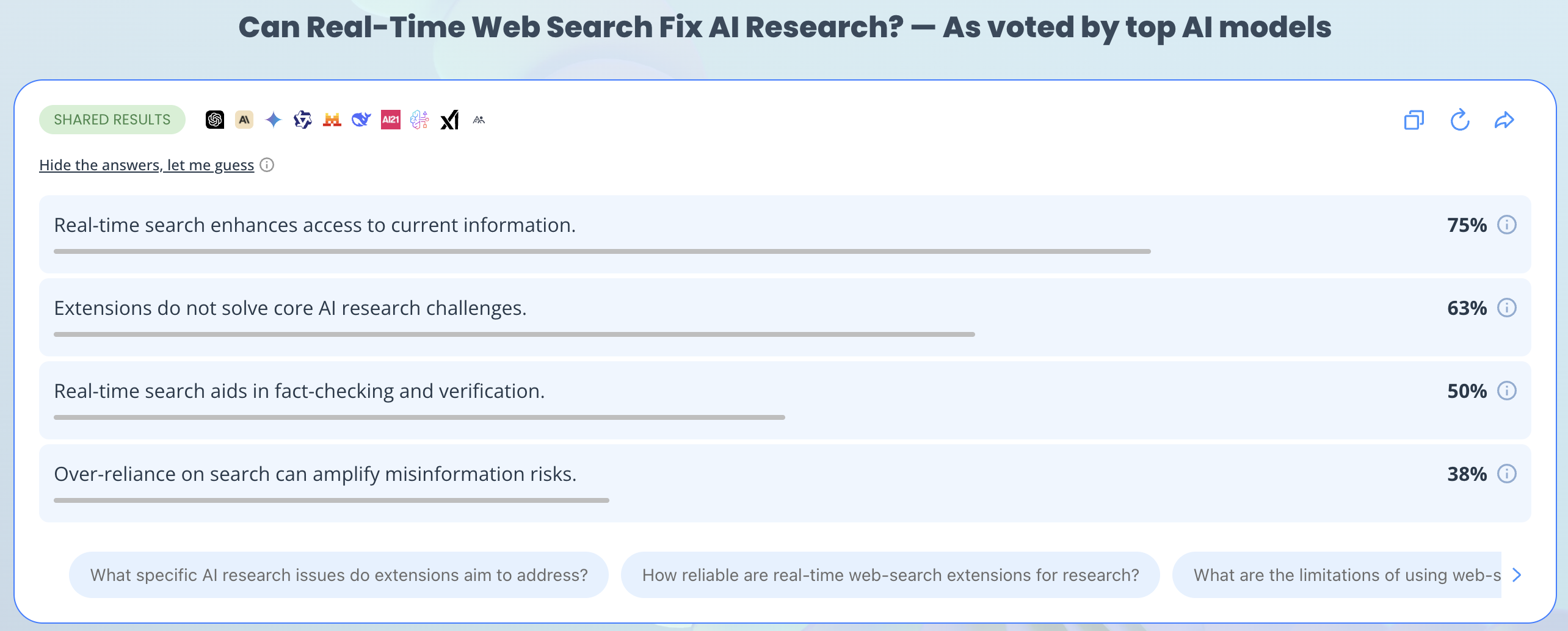
Manually jumping between four browser tabs to verify a single data point is a massive productivity killer. Eye2.AI automates the entire verification process through frictionless, parallel processing.
Simultaneous model execution: When you input a complex research query or upload a text dataset into Eye2.AI, it triggers response streams across 12+ separate model architectures simultaneously.
The SMART result and Shared Results section: The platform visually calculates the percentage of alignment between the different outputs. If different models built on completely distinct codebases match up on a specialized metric, your statistical certainty spikes.
Instant outlier filtering: If Gemini and Claude give you identical structural data for a corporate analysis, but ChatGPT pulls an incorrect number out of thin air, Eye2.AI's side-by-side layout exposes the outlier instantly before it can leak into your final presentation.
FAQs
1. Can real-time web-search extensions fix the AI research problem?
No. Evaluations confirm that even when models are plugged directly into active search engines, they still regularly retrieve conflicting sources, misinterpret complex source text, or confidently cite a real link for a claim it doesn't actually support.
2. Which AI model is currently the most reliable for text extraction?
According to recent factual consistency benchmarks, Google's Gemini 2.5 Flash-Lite holds one of the lowest enterprise error rates at 3.3%, outperforming several heavier reasoning models that are more prone to over-analyzing and inventing details.
3. Is Eye2.AI safe for processing proprietary corporate data?
Yes. By requiring no account signup, no email, and no registration, Eye2.AI ensures your sensitive research queries do not create a permanent tracking profile, offering professional privacy with zero feature compromises.
By using Eye2.ai, you agree to the Terms and Privacy Policy. Outputs may contain errors.
Download the Eye2.ai app on: