ChatGPT vs. Claude vs. Gemini: The "Strawberry" Test
Updated| February 6, 2026
We asked 9 top AI models to count the 'r's in "Strawberry." See why ChatGPT and Claude failed while Gemini and Llama passed in this Eye2.AI comparison.
TL;DR: We ran the viral "Strawberry" logic test through Eye2.AI to see which models could count to three. The results were a shocking near-even split. While industry darlings ChatGPT and Claude failed, a coalition of rivals led by Gemini and Llama successfully navigated the tokenization trap.
Table of Contents
What is the hypothesis?
How did we test it?
What does the data show?
Why did the "giants" fail?
Why did the "underdogs" win?
What is the verdict?
FAQs
What is the hypothesis?
You would expect an AI that can write Python code to be able to count letters in a word. However, the "Strawberry Test" exposes a fundamental flaw in how Large Language Models (LLMs) process text: Tokenization. Models don't read letter-by-letter; they read in chunks.
Our Question: Can the top LLMs overcome their "token blindness" to answer a simple question, or will they hallucinate?
How did we test it?
We used Eye2.AI to query the leading models simultaneously with a single prompt.
Prompt: "Count the 'r' in 'strawberry'."
Goal: Identifying the correct count (3).
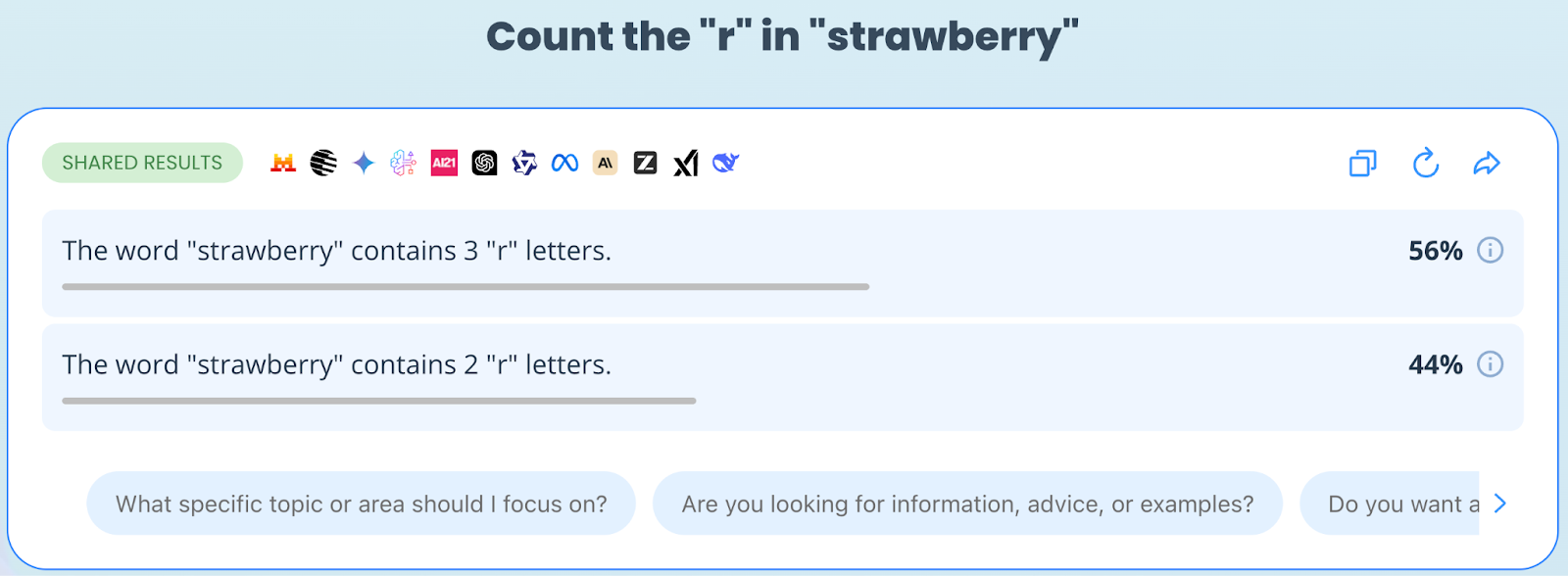
What does the data show?
The consensus engine returned a 56% vs. 44% split, proving that "intelligence" is not evenly distributed across simple tasks.
Result | Models | Accuracy |
"There are 2 'r's" | 🔴 ChatGPT (OpenAI) 🔴 Claude (Anthropic) 🔴 Mistral 🔴 Amazon Nova | FAIL (44%) |
"There are 3 'r's" | 🟢 Gemini (Google) 🟢 Llama (Meta) 🟢 Qwen (Alibaba) 🟢 Grok (xAI) 🟢 DeepSeek | PASS (56%) |
Why did the "giants" fail?
It seems impossible that ChatGPT and Claude (widely considered the smartest models) failed this test. The reason is technical, not intellectual.

The "Chunking" Problem: LLMs do not see the word Strawberry as S-t-r-a-w-b-e-r-r-y. They see it as numeric tokens, likely breaking it down into [Straw] and [berry].
The Blind Spot: The "r"s are hidden inside the tokens. Unless the model "unpacks" the word (by spelling it out first), it relies on a probabilistic guess.
The Hallucination: The model confidently says "2" because the token [berry] is a single unit to it, and it struggles to "look inside" that unit to count the double 'r'.
Why did the "underdogs" win?
The success of Gemini, Llama, and Qwen suggests they are handling this specific friction point better.
Overfitting/Training Data: Because this riddle went viral, newer model updates (like Gemini 1.5 and Llama 3) likely have this specific "riddle" in their training data, allowing them to answer from memory rather than counting.
Better Tokenizers: Some models use different tokenization libraries that might break words down more granularly, making the letters more "visible" to the model.
What is the verdict?
If you had relied solely on Claude for data extraction, you would be wrong.
If you had relied solely on Llama, you would be right.
This proves that brand name ≠ accuracy. The only way to be safe is to check the consensus. When 44% of models say "2" and 56% say "3," Eye2.AI flags the risk so you don't look foolish in a report.
FAQs
1. Why is counting letters so hard for AI?
AIs don't "read" like humans. They use Tokenization, which turns words into numerical IDs. For example, "Strawberry" might be Token ID 496 + 15717. The model can't "see" the letters inside those IDs unless it is forced to spell the word out first.
2. Does this mean ChatGPT is "dumb"?
No. It means it is a Language model, not a Character model. It excels at writing poetry and code but struggles with sub-word tasks. This is like asking a calculator to write a poem, it's the wrong tool for that specific micro-task.
3. How can I fix this in my own prompts?
Use "Chain of Thought" prompting. Instead of asking "Count the 'r's," ask: "Spell out the word 'strawberry' and then count the 'r's." This forces the model to break the tokens down, usually resulting in the correct answer.
By using Eye2.ai, you agree to the Terms and Privacy Policy. Outputs may contain errors.
Download the Eye2.ai app on: