Why the smartest thinking AI models still fail at basic logic
Updated| June 1, 2026
Think the newest "thinking" AI models are infallible? Watch them completely collapse on basic logic riddles. Learn how Eye2.AI spots these reasoning flaws instantly.
Ofer Tirosh is the founder and CEO of Tomedes, a language technology and translation company that supports business growth through a range of innovative localization strategies. He has been helping companies reach their global goals since 2007.
TL;DR: The race for artificial intelligence in 2026 has entered its most deceptive phase. While advanced "System 2" reasoning models can write flawless code and pass the bar exam, they are completely blindsided by simple human common sense. Recent evaluations show that while frontier models excel at advanced mathematics, their reliability plunges to a staggering 0% accuracy on basic logic riddles if you change a single irrelevant detail. Eye2.AI exposes these structural blind spots by letting you cross-examine multiple reasoning engines side-by-side, preventing you from mistaking eloquent language for actual intelligence.
Table of Contents
The illusion of logic and how AIs fake the thinking process Three common reasoning flaws that fool everyday users The hidden cost of blind trust in high-stakes industries How Eye2.AI uses model divergence to find the truth Frequently asked questions
The illusion of logic and how AIs fake the thinking process
The biggest trick in the AI landscape today is the "Thinking" placeholder. When a model pauses for several seconds to "reason" through a prompt, it isn't experiencing a human-like epiphany.
The token trap: "Thinking" models are simply generating thousands of invisible internal tokens to break a problem down step-by-step. They are still relying on statistical probability, not actual logic.
The rehearsal bias: An AI model performs brilliantly on a complex physics equation because that equation (or variations of it) existed thousands of times in its training data. It is repeating a memorized path, not inventing a solution.
The formatting flaw: Because these models are optimized to sound incredibly confident and follow rigid structures, a reasoning flaw looks exactly like a logical truth to the untrained eye.
Three common reasoning flaws that fool everyday users
When forced outside of their comfort zones, even the most expensive enterprise models stumble over simple logical hurdles.
The Reverse Priming Trap: If you ask a standard model, "If it takes 5 towels 5 hours to dry on a clothesline, how long does it take 10 towels to dry?" a reasoning model will often over-complicate the math and confidently answer "10 hours." It misses the real-world physics entirely.
The Alice in Wonderland Failure: In a famous AI benchmark test, models are asked: "Alice has three brothers. Each of her brothers has one sister. How many sisters does Alice have?" Because the AI focuses heavily on matching patterns rather than drawing a family tree, it frequently outputs "three" instead of realizing that Alice is the sister.
The Irrelevant Detail Collapse: If you paste a standard logic riddle but inject a meaningless sentence in the middle (e.g., "and then John put on a blue hat"), the reasoning model will often derail its entire deduction trying to calculate the mathematical value of the blue hat.
The hidden cost of blind trust in high-stakes industries
When an AI experiences a reasoning flaw in creative writing, it's funny. When it happens in enterprise workflows, it is financially catastrophic.
In Software Engineering: A coding assistant might reason its way through a brilliant data sorting script, but completely fail to realize that the code introduces a massive, elementary security vulnerability to the database architecture.
In Financial Auditing: Reasoning models are excellent at parsing spreadsheets, but they can easily fall prey to order-of-operations confusion when interpreting non-standard corporate financial disclosures, leading to inaccurate risk assessments.
In Legal Analysis: An AI might brilliantly synthesize case law but completely fail a basic logic test regarding jurisdictional overlapping, leading an attorney to file an invalid motion.
How Eye2.AI uses model divergence to find the truth
You cannot rely on a single AI model to police its own logic. Because it doesn't know it's failing, it will never warn you. Eye2.AI breaks this trap through parallel validation.
Exposing the outliers: When you enter a complex prompt on Eye2.AI, it fires across 12+ separate model architectures simultaneously. If ChatGPT, Claude, and Gemini provide three wildly different logical pathways, the platform's layout alerts you instantly that the logic is broken.
The Agreement Meter check: If multiple models from entirely different parent companies arrive at the exact same logical conclusion, your statistical certainty spikes.
Frictionless sanity checks: Because Eye2.AI requires no login and no account, you can quickly paste sensitive code or logical arguments to run an immediate sanity check across the entire AI ecosystem without leaving a permanent data trail.
FAQs
1. Why do smaller "Flash" models sometimes beat "Thinking" models at logic?
Smaller models stick closer to the explicit text of your prompt. Heavy reasoning models are engineered to extrapolate and look for hidden patterns; when there are no hidden patterns, they frequently over-think and invent complications that aren't there.
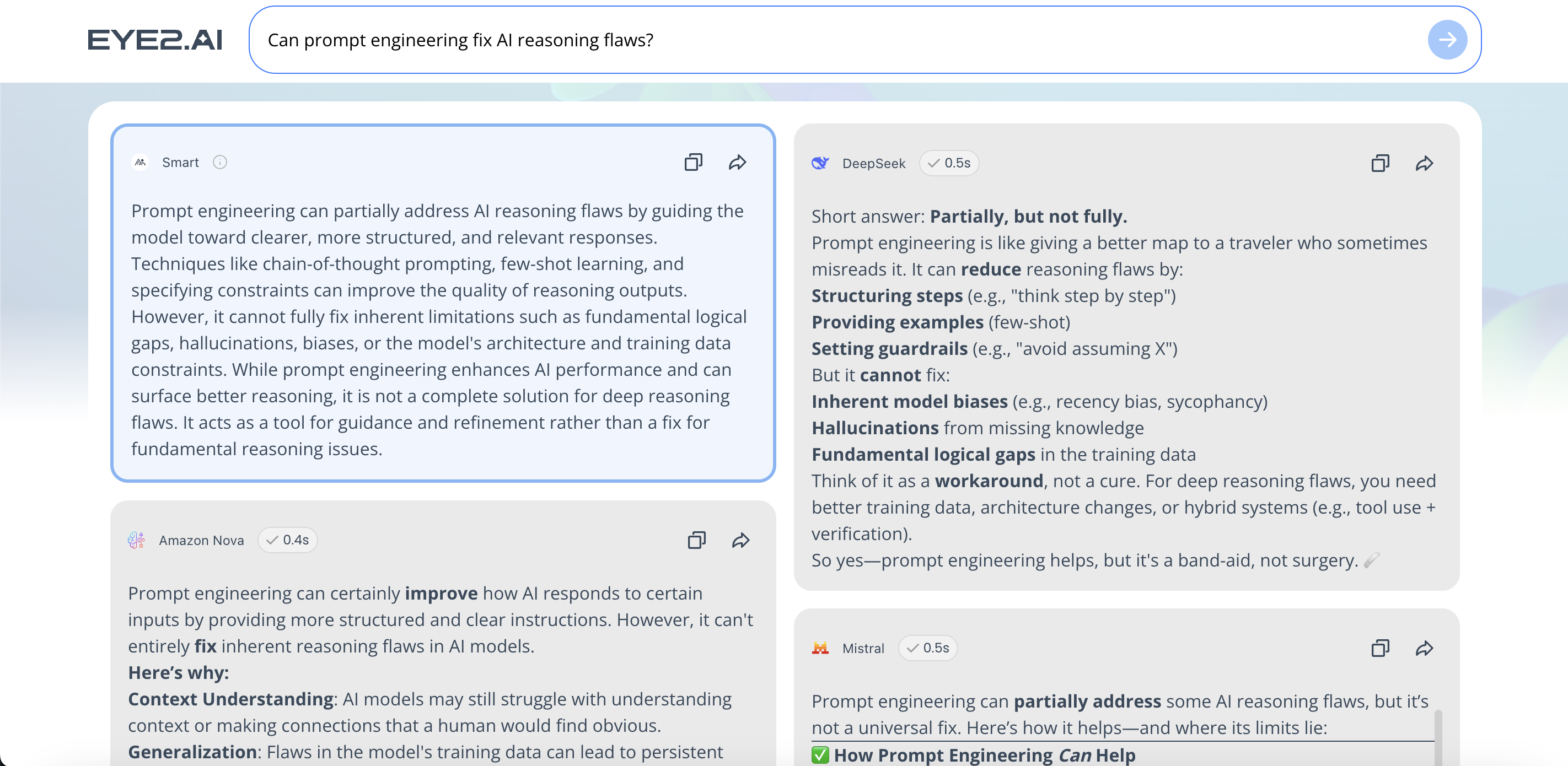
2. Can prompt engineering fix AI reasoning flaws?
It helps, but it isn't a cure. Adding phrases like "Think step-by-step" or "Check your work for common sense" forces the model to use more tokens, which reduces simple mathematical slips but still fails if the underlying problem requires genuine spatial or conceptual understanding.
3. How can I spot a reasoning flaw on Eye2.AI?
Look for divergence. If you run a prompt and the side-by-side view shows that the models are contradicting each other's core arguments, you have successfully exposed a logical blind spot.
By using Eye2.ai, you agree to the Terms and Privacy Policy. Outputs may contain errors.
Download the Eye2.ai app on: